Weakly Supervised Representation Learning for Audio-Visual Scene Analysis
Sanjeel Parekh Slim Essid Alexey Ozerov Ngoc Duong Patrick Pérez Gaël Richard
TASLP 2019 Companion Website
Abstract
Audio-visual representation learning is an important task from the perspective of designing machines with the ability to understand complex events. To this end, we propose a novel multimodal framework that instantiates multiple instance learning. We show that the learnt representations are useful for performing several tasks such as event/object classification, audio event detection, audio source separation and visual object localization. The system is trained using only video-level event labels without any timing information. An important feature of our method is its capacity to learn from unsynchronized audio-visual events. We also demonstrate our framework's ability to separate out the audio source of interest through a novel use of nonnegative matrix factorization. State-of-the-art classification results are achieved on DCASE 2017 smart cars challenge data with promising generalization to diverse object types such as musical instruments. Visualizations of localized visual regions and audio segments substantiate our system's efficacy, especially when dealing with noisy situations where modality-specific cues appear asynchronously.
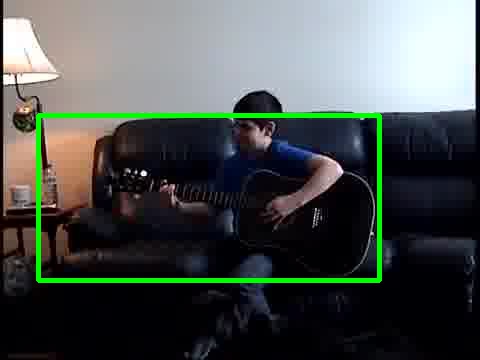
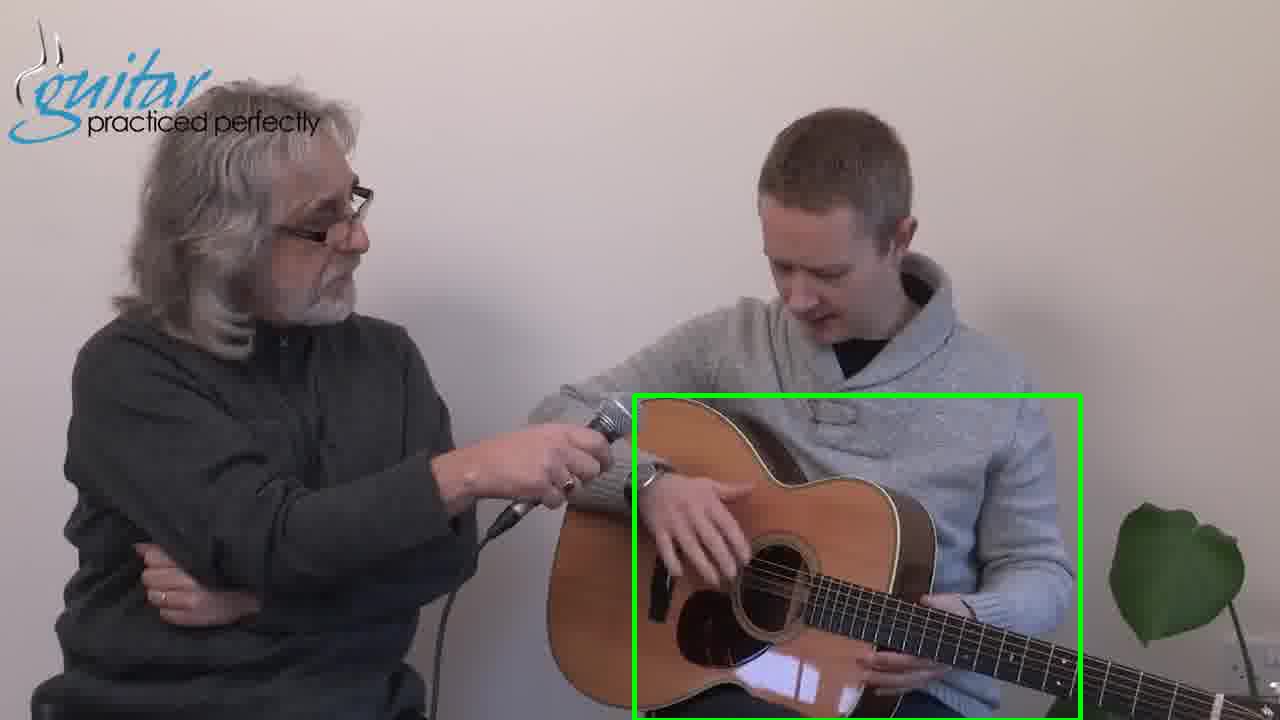
Visual Localization Examples - Kinetics Instruments
accordion
bagpipes
guitar
violin
Some failure cases (video ground truth class in red )
object (harmonica) too small and occluded
multiple object instance grouping and visual clutter (bagpipes and violin)
intra-class variation (xylophone) and visual clutter
Source Separation Examples
Computed using audio-only NCP system in "Label Known" mode
Separating instrument sounds from "in-the-wild" YouTube videos
We perform hard thresholding ( τ = 0.1, as explained in the paper). Note that there is no assumption on the number of sources in the mixture.
For each separation result below the NMF is randomly initialized.
To play the audio click on the link between square brackets [ ]
Uploading more examples soon!